
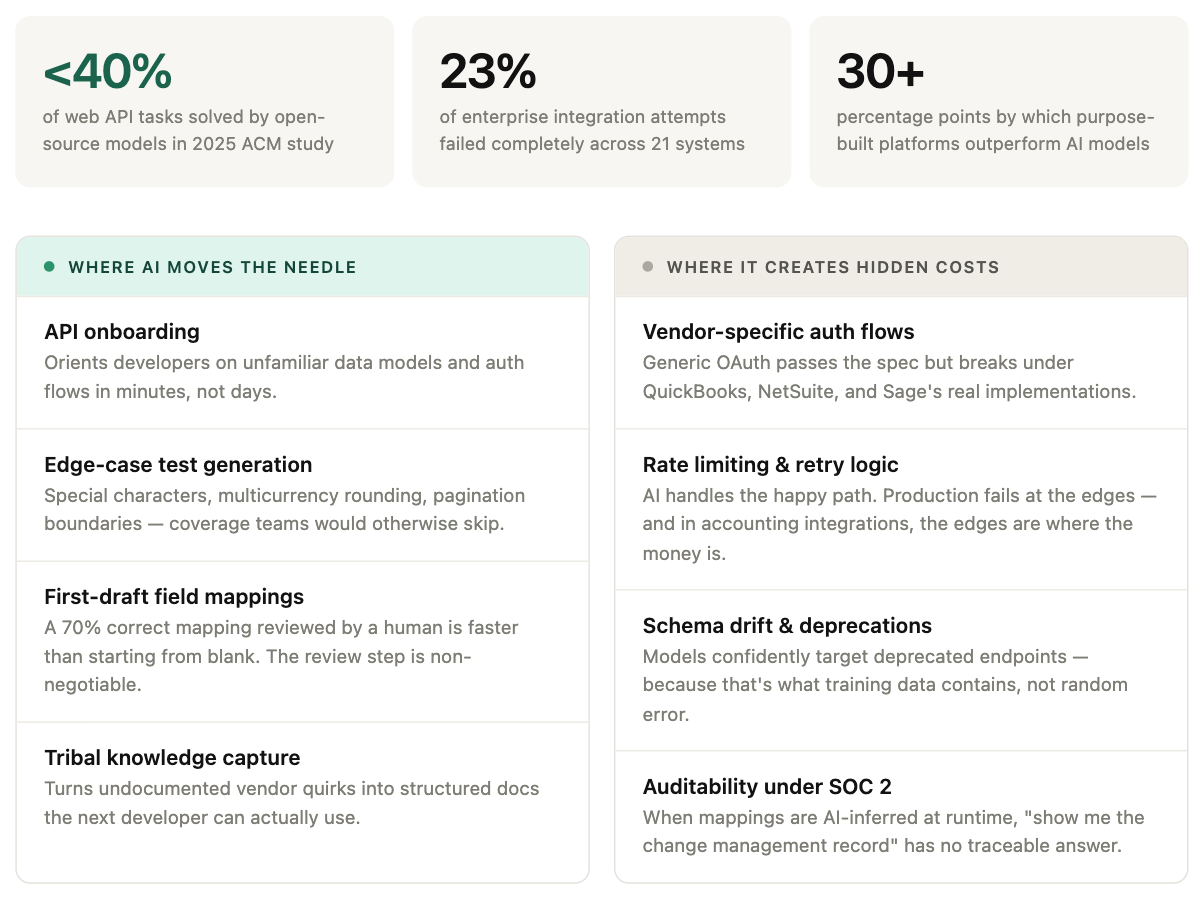
AI tools can generate API calls and connector code in minutes. The problem is that production integrations are not API calls. They are authentication flows with OAuth variations across vendors, webhook handling, pagination logic, rate limiting, retry mechanisms, idempotency guarantees, schema transformations, version management, and the security posture that keeps all of it from becoming an attack surface. AI-generated code typically handles the happy path and fails at the edges. In accounting and ERP integrations, the edges are where the money is.
None of this means avoiding AI entirely. The more useful question is where AI genuinely moves the needle versus where it creates hidden costs that surface later. Both are real, and conflating them leads to bad decisions in either direction.
The iceberg problem is worse than it looks
When a developer asks an AI to integrate QuickBooks, it generates something that works against the sandbox in about ten minutes. Stakeholders see this and conclude the integration is nearly done. In practice, that visible progress represents around 20% oThe complexity that used to live in explicit field mappings and error handling code now lives in prompts, context, and implicit assumptions.f the actual work.
The remaining 80% is invisible: handling token refresh failures when the user's QuickBooks session expires mid-sync, retrying on rate limit responses without hammering the API, managing the difference between a draft invoice and a posted one, dealing with line items that contain characters QuickBooks silently truncates. None of this appears in documentation. It shows up in production, usually at the worst moment.
A 2025 study presented at the ACM International Conference on AI-powered Software found that none of the evaluated open-source models solved more than 40% of web API integration tasks. The failures were not random. They clustered around exactly these edge conditions: hallucinated endpoints, incorrect pagination handling, authentication flows that worked against documented behavior but failed under real vendor implementations.
The Superglue Integration Benchmark, which tested 21 enterprise systems across six AI models, found that 23% of integration attempts failed completely. Only six systems integrated 100% reliably across all platforms tested. The benchmark's conclusion: purpose-built integration platforms outperform general AI models by 30+ percentage points on real enterprise workflows.
The security implications compound the reliability problem. Wallarm's 2026 API ThreatStats report found that APIs are now the single largest exploited vulnerability surface, with 97% of API vulnerabilities exploitable in a single request. AI vulnerabilities grew 398% year over year. When AI generates integration code that handles authentication loosely or passes untrusted input to downstream systems, it creates exactly the attack vectors this report documents.

AI doesn't hallucinate randomly. It hallucinates predictably.
This is underappreciated. AI models fail at integrations in consistent, specific ways that reflect their training data rather than random noise.
Enterprise APIs like NetSuite have massive API surfaces that are version-dependent and sparsely documented in public sources. AI-generated code for NetSuite consistently targets deprecated endpoints and uses authentication patterns from older API versions, because that is what the training data contains. The model is not guessing randomly; it is confidently using what it learned, which happens to be wrong.
The same pattern appears across accounting platforms. QuickBooks Online uses OAuth 2.0 with specific token refresh requirements that differ from generic OAuth 2.0 implementations. Sage Intacct uses session-based authentication. NetSuite supports multiple authentication methods with different scoping rules. AI generates a generic OAuth flow that satisfies the documented standard but fails under vendor-specific requirements. These are not bugs in the AI; they are the predictable output of training on documentation rather than on the vendor support tickets and community forum posts where the real behavior is described.
In March 2026, Andrew Ng's team at DeepLearning.AI released Context Hub, an open-source CLI tool designed to give coding agents access to curated, versioned API documentation. The tool addresses what Ng calls "agent drift," where models rely on static training data and hallucinate parameters that no longer exist. It is useful. It also makes the core problem explicit: reliable integration code requires grounding in current, vendor-specific documentation that someone has to maintain. AI cannot create that grounding layer. It can only use one that already exists.
The data transformation problem is harder than it appears
When AI maps fields between systems, it makes reasonable-sounding assumptions that are often wrong in ways that pass type checks.
Consider a vertical SaaS company syncing invoices across QuickBooks, NetSuite, Xero, and Sage. Invoice lifecycle states vary across all four: some use "draft" and "finalized," others use "pending," "approved," and "posted." Tax handling diverges based on regional requirements. Currency conversions follow different rounding rules. Line item structures use incompatible schemas. A field named "status" in one system does not map to "status" in another, and AI does not know this unless explicitly told.
An invoice posted twice is a reconciliation nightmare. A payment applied to the wrong customer creates downstream cascades in reporting and collections. A sync that silently drops records under rate limiting leaves data gaps that surface weeks later during audits. These are not abstract technical problems. They are the specific failure modes of data transformation code that looked correct but carried wrong semantic meaning. This is the same challenge that makes ERP API integration one of the most underestimated engineering efforts in B2B software.
AI hides complexity instead of solving it
This is the most important point and it rarely gets said clearly: AI-assisted integration development relocates complexity rather than eliminating it. This trade-off is especially important in enterprise software development, where architectural decisions must remain explicit, maintainable, and fully auditable to ensure long-term reliability and compliance. The complexity that used to live in explicit field mappings and error handling code now lives in prompts, context, and implicit assumptions. Using a prompt generator to write clearer, more structured prompts can at least make some of that hidden complexity more explicit and easier to review.
Explicit configuration is inspectable. When an integration fails, you look at the field mapping rules and find the problem. When an AI inferred the mapping, debugging means reverse-engineering what the model decided and why it decided differently for certain records. The integration works 99% of the time, and the 1% failure compounds into data quality issues that take weeks to trace.
For accounting and ERP integrations, where data accuracy has financial and regulatory implications, this is a serious problem. When an auditor reviews a data sync pipeline during a SOC 2 examination, they don't ask "does it work." They ask: show me the access control policy for the credentials this pipeline uses. Show me the rotation schedule. Show me the logs that prove only authorized services accessed customer financial data in the last 90 days. Show me the change management record for the last time this field mapping was modified, who approved it, when, and what was the business justification.
When your field mappings are explicit configuration in version control, every one of those questions has a traceable answer. When an AI inferred the mapping at runtime, the answer is "the model decided." That is not a control. That is a finding.
The limitations of AI-generated integrations are becoming clear even to companies building AI-first products. In March 2026, Perplexity's cofounder and CTO announced that they're moving away from MCP integrations entirely, shifting back to traditional APIs and CLIs. David Zhang, whose team at Duet built full MCP support including OAuth and dynamic client registration, documented why they deleted the feature: context bloat.
Every MCP tool definition burns tokens before the agent does anything useful. Connect ten services with five tools each and you've consumed thousands of tokens on tool schemas alone. The alternative Zhang describes, agents that write their own integration code on demand, sounds elegant until you consider what that code actually does: the same authentication flows, retry logic, and schema transformations this article has been discussing. The agent might write the integration, but someone still has to maintain the infrastructure it runs on, handle the vendor-specific edge cases, and deal with API deprecations. Self-evolving software is a compelling vision. It is not a substitute for professionally maintained integration infrastructure.
AI gives the illusion that you can build anything
The ten-minute QuickBooks demo creates a dangerous confidence. If AI can generate working API calls in minutes, the reasoning goes, then the build-versus-buy calculus has fundamentally changed. Why pay for integration infrastructure when you can just generate it?
This logic fails because it conflates the visible and invisible parts of the iceberg. AI makes the visible part faster. It does not touch the invisible part. The authentication edge cases, the rate limiting, the schema drift, the vendor-specific quirks, the security posture, the monitoring, the maintenance across API version changes: none of this gets easier because AI wrote the initial code. In some ways it gets harder, because the AI-generated codebase carries architectural decisions that are difficult to understand or modify when the original reasoning is not documented anywhere.
The illusion is especially dangerous for teams that have not built integrations before. They see the demo, assume the hard part is done, and commit to timelines based on the 20% they can see. The remaining 80% surfaces during implementation, but by then the project is already staffed and the deadline is set. The result is either a rushed integration that breaks in production or a delayed launch that costs more than buying infrastructure would have.
The maintenance math is not what it looks like
The commonly cited argument for AI-assisted integration development is that it reduces initial development time significantly, changing the build-versus-buy calculation. This analysis is missing most of the cost.
QuickBooks releases major API versions annually with deprecation windows. NetSuite's API evolves with each product release. Xero introduces breaking changes with limited notice. For each integration, an engineering team needs to monitor for changes, test against new versions, update code, and deploy before deprecation deadlines affect customers. A company supporting ten accounting integrations, eight CRM integrations, and six HR integrations is tracking 24 separate APIs, each evolving independently, with no relationship to the others.
AI may reduce initial development time. It does not reduce monitoring, testing, or migration work. For teams that discover this after building, the AI-generated codebase often carries an additional maintenance penalty: the original generation made architectural decisions that are difficult to understand or modify, because the reasoning behind them is not documented anywhere.
Integration platforms spread maintenance costs across their entire customer base. When QuickBooks releases a new API version, the platform handles the migration once. All customers benefit. The economics are most compelling for companies needing integrations across multiple categories, which is most B2B SaaS companies at scale.
Where AI actually moves the needle
These limitations define boundaries, not a verdict. All of the above describes what AI cannot reliably do in production integration infrastructure. It is not an argument against using AI. It is an argument for understanding where AI reduces real costs versus where it creates hidden ones.
Onboarding to unfamiliar APIs is dramatically faster. The hardest part of starting a new integration is not writing the code. It is understanding the data model. What does "posted" mean in this system? How does this vendor handle multicurrency? What is the difference between a bill and a vendor credit? Historically this meant hours of documentation reading, forum digging, and sandbox experimentation before writing a single line. AI compresses this. A developer who has never touched Sage Intacct can get oriented on the object model, understand the auth flow, and identify the gotchas worth testing for in minutes rather than days. The output is not production-ready code. The value is the developer arriving at the keyboard already knowing what questions to ask.
Test coverage that would otherwise get skipped also improves. Integration test suites are typically thin because writing them is tedious. Generating realistic edge-case test data (invoices with special characters, zero-amount line items, multicurrency with unusual rounding, records at pagination boundaries) is exactly the kind of mechanical work AI handles well. Teams that use AI for test generation consistently end up with broader coverage than they would have written manually, which means they catch semantic errors before they reach production rather than after.
AI is also useful for documenting tribal knowledge. The undocumented behaviors that live in support tickets and community forums represent real institutional value. AI does not generate this knowledge, but it is useful for capturing and structuring it. The developer who has fought with NetSuite's concurrency limits for two years can describe the behavior conversationally and get back structured documentation the next developer can actually use. That knowledge transfer used to require pairing time.
Field mapping works best as a first draft, not a final answer. The data transformation failures described above happen when AI output is treated as production configuration. If teams treat AI-generated field mappings as a first draft that gets reviewed by someone who knows both systems, the dynamic changes. Starting from a mapping that is 70% correct and needs human review is faster than starting from a blank schema. The error mode is only dangerous when the review step is skipped.
A safer architecture
The practical answer is not to avoid AI, but to use it where it accelerates development without controlling production data flows.
Use AI during development, not at runtime. Field mappings, transformation rules, and business logic should exist as documented configuration that engineers can inspect and modify, not as AI inference. The hardest parts of integrations (authentication, error handling, retry logic, rate limiting, and maintenance) should run on reliable infrastructure, not on model output.
The architecture that actually works in practice splits the problem in two. A unified API platform handles the infrastructure: authentication, pagination, rate limiting, schema normalization across more than 200 connectors spanning CRM, accounting, HRIS, eCommerce, and the rest. Your engineering team and your AI tooling build against one stable interface instead of fighting each vendor's API individually. That is what Apideck does. AI handles the application logic on top. The integration infrastructure underneath is someone else's problem, professionally maintained.
The real question for engineering leadership
The strategic question is not whether AI can generate integration code. It can. The question is whether that changes where engineering time should go.
Most B2B SaaS companies that have thought carefully about this reach the same conclusion: integrations are necessary but not differentiating. They are infrastructure, and infrastructure that your engineering team owns is infrastructure your engineering team maintains indefinitely. The opportunity cost is the product work that does not get built because the sprint was spent debugging a QuickBooks API deprecation that your integration platform would have handled automatically.
AI changes a lot about software development. It does not change the fundamental economics of integration maintenance, the necessity of vendor-specific expertise, or the value of having someone else own the problem. What it does change is the cost of the development work that sits on top of reliable infrastructure: orientation, test generation, documentation, first-draft mapping. These are real costs, and AI reduces them meaningfully.
The combination of reliable infrastructure and AI-assisted development is genuinely better than either alternative alone. The mistake is conflating the two and assuming that because AI helps with one, it can substitute for the other.
Ready to get started?
Scale your integration strategy and deliver the integrations your customers need in record time.







